转载来自:
Webdriver
Selenium 是 ThroughtWorks 一个强大的基于浏览器的开源自动化测试工具,它通常用来编写 Web 应用的自动化测试。
Selenium 2,又名 WebDriver,它的主要新功能是集成了 Selenium 1.0 以及 WebDriver(WebDriver 曾经是 Selenium 的竞争对手)。也就是说 Selenium 2 是 Selenium 和 WebDriver 两个项目的合并,即 Selenium 2 兼容 Selenium,它既支持 Selenium API 也支持 WebDriver API。
下载安装:
下载地址(2015-06-04更新):
安装:
setup.py install
简单示例:
# -*- coding: UTF8 -*-from selenium import webdriverimport time #调入time函数browser = webdriver.Firefox()url= 'http://email.163.com/#from=ntes_product'browser.get(url)browser.maximize_window() #将浏览器最大化显示browser.find_element_by_id("userNameIpt").send_keys("webdriver123")time.sleep(0.3) #休眠0.3秒browser.find_element_by_id("pwdPlaceholder").send_keys("webdriver321")browser.find_element_by_id("btnSubmit").click()time.sleep(5) #休眠5秒browser.find_element_by_css_selector("#dvNavTop ul li:nth-child(2)").click() # :nth-child(2)选取第几个标签,“2可以是你想要的数字”time.sleep(0.3) #休眠0.3秒browser.find_element_by_class_name("nui-editableAddr-ipt").send_keys('abc123@163.com')time.sleep(0.3) #休眠0.3秒browser.find_element_by_css_selector(".tH0 .nui-ipt-input").send_keys('test webdriver')time.sleep(0.3) #休眠0.3秒browser.find_element_by_class_name("APP-editor-iframe").send_keys('test webdriver content')time.sleep(0.3) #休眠0.3秒browser.find_element_by_css_selector(".jp0 .nui-btn-icon").click()time.sleep(0.3) #休眠0.3秒 说明:
引入webdriver
from selenium import webdriver
操作浏览器 (浏览器可支持IE、Firefox、Chrome)
browser = webdriver.Firefox()
然后通过模拟发送send_keys数据,模拟点击事件click(), 简单的示例是登录163邮箱,发送邮件。
为什么要添加time.sleep()? 因为要看脚本运行过程 、 因为页面没有加载完成,直接调取不存在元素会报错
对象属性
browser.find_element_by_id("btnSubmit").click() click() : 模拟点击事件
browser.quit() # or browser.close()
quit() 或 close() 退出并关闭窗口的每一个相关的驱动程序
browser.maximize_window()
maximize_window() 浏览器最大化
browser.set_window_size(480, 800) #参数数字为像素点
set_window_size(480, 800) 设置浏览器固定宽、高
browser.back()browser.forward()
back() 浏览器返回按钮操作,forward() 浏览器前进按钮操作
js = "$('.logo').css('border', '1px solid red');"browser.execute_script(js) execute_script() 执行js脚本
browser.find_element_by_id("kw").clear() clear() 用于清除输入框的内容,比如百度输入框里默认有个“请输入关键字”的信息,再比如我们的登陆框一般默认会有“账号”“密码”这样的默认信息。clear可以帮助我们清除这些信息。
简单对象的定位
对象的定位应该是自动化测试的核心,要想操作一个对象,首先应该识别这个对象。
定位对象的目的一般有下面几种
- 操作对象
- 获得对象的属性,如获得测试对象的class属性,name属性等等
- 获得对象的text
- 获得对象的数量
webdriver提供了一系列的对象定位方法,常用的有以下几种
- id
- name
- class name
- link text
- partial link text
- tag name
- xpath
- css selector
#通过id方式定位browser.find_element_by_id("kw").send_keys("selenium") #通过name方式定位browser.find_element_by_name("wd").send_keys("selenium") #通过tag name方式定位browser.find_element_by_tag_name("input").send_keys("selenium") #通过class name 方式定位browser.find_element_by_class_name("s_ipt").send_keys("selenium") #通过CSS方式定位browser.find_element_by_css_selector("#kw").send_keys("selenium") #通过xphan方式定位browser.find_element_by_xpath("//input[@id='kw']").send_keys("selenium") #通过link 定位browser.find_element_by_link_text("贴 吧").click() #通过部分链接定位browser.find_element_by_partial_link_text("贴").click()
定位一组元素
webdriver可以很方便的使用findElement方法来定位某个特定的对象,不过有时候我们却需要定位一组对象,比如将页面上所有的checkbox都勾上。先获取一组对象,再在这组对象中过滤出需要具体定位的一些对象。比如定位出页面上所有的checkbox,然后选择最后一个。
第一种方法:
通过浏览器打个这个页面我们看到三个复选框和两个单选框。下面我们就来定位这三个复选框。
# -*- coding: utf-8 -*-from selenium import webdriverimport timeimport osdr = webdriver.Firefox()file_path = 'file:///' + os.path.abspath('checkbox.html')dr.get(file_path)# 选择页面上所有的input,然后从中过滤出所有的checkbox并勾选之inputs = dr.find_elements_by_tag_name('input')for input in inputs: if input.get_attribute('type') == 'checkbox': input.click()time.sleep(2)dr.quit() 第二种定位方法:
# -*- coding: utf-8 -*-from selenium import webdriverimport timeimport osdr = webdriver.Firefox()file_path = 'file:///' + os.path.abspath('checkbox.html')dr.get(file_path)# 选择所有的checkbox并全部勾上checkboxes = dr.find_elements_by_css_selector('input[type=checkbox]')for checkbox in checkboxes: checkbox.click()time.sleep(2)# 打印当前页面上有多少个checkboxprint len(dr.find_elements_by_css_selector('input[type=checkbox]'))time.sleep(2)dr.quit() 第二种写法与第一种写法差别不大,都是通过一个循环来勾选控件
find_elements_by_css_selector(css_selector)
#查找并返回多个元素的CSS 选择器列表
层级定位
在实际的测试中也经常会遇到这种问题:页面上有很多个属性基本相同的元素,现在需要具体定位到其中的一个。由于属性基本相当,所以在定位的时候会有些麻烦,这时候就需要用到层级定位。先定位父元素,然后再通过父元素定位子孙元素
保存该文件,在浏览器打开:
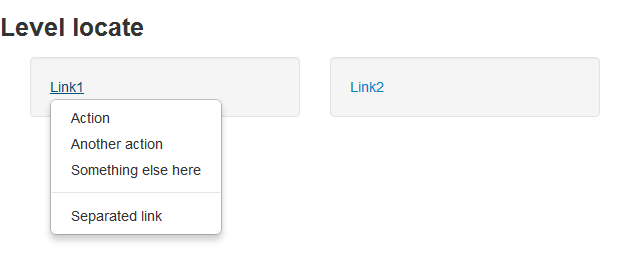
这里自制了一个页面,上面有两个文字链接,点击两个链接会弹出一模一样的的两个下拉菜单,这两个菜单的属性基本一样。那么我如何区分找到相应的菜单项呢?
方法如下:
# -*- coding: UTF8 -*-from selenium import webdriverimport timeimport osdr = webdriver.Firefox()file_path = 'file:///' + os.path.abspath('autohtml.html')dr.get(file_path)#点击Link1链接(弹出下拉列表)dr.find_element_by_link_text('Link1').click()#在父亲元件下找到link为Action的子元素menu = dr.find_element_by_id('dropdown1').find_element_by_link_text('Action')#鼠标定位到子元素上webdriver.ActionChains(dr).move_to_element(menu).perform()time.sleep(2) class ActionChains(driver)
driver: 执行用户操作实例webdriver
生成用户的行为。所有的行动都存储在actionchains对象。通过perform()存储的行为。
move_to_element(menu)
移动鼠标到一个元素中,menu上面已经定义了他所指向的哪一个元素
to_element:元件移动到
perform()
执行所有存储的行为
需要我们日常工作中细细品味、慢慢消化这些函数的用法
效果:
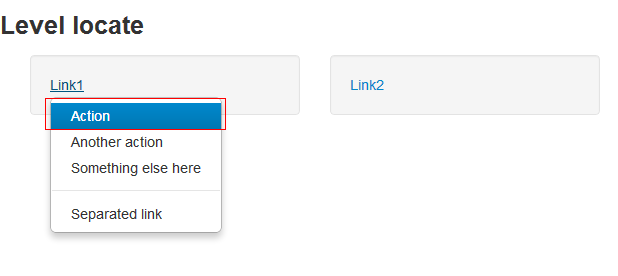
元素操作
WebElement 另一些常用方法:
- text 获取该元素的文本
- submit 提交表单
- get_attribute 获得属性值
text
#id = cp 元素的文本信息data=driver.find_element_by_id("cp").textprint data #打印信息 结果: ©2015 Baidu 使用百度前必读 意见反馈 京ICP证030173号
submit
#通过submit() 来操作driver.find_element_by_id("su").submit() 这里用submit 与click的效果一样,我暂时还没想到只能用submit 不能用click的场景。
get_attribute
获得属性值
select = driver.find_element_by_tag_name("select")allOptions = select.find_elements_by_tag_name("option")for option in allOptions: print "Value is: " + option.get_attribute("value") option.click()
多层框架或窗口的定位:
- switch_to_frame()
- switch_to_window()
对于一个现代的web应用,经常会出现框架(frame) 或窗口(window)的应用,这也就给我们的定位带来了一个难题。
有时候我们定位一个元素,定位器没有问题,但一直定位不了,这时候就要检查这个元素是否在一个frame中,seelnium webdriver 提供了一个switch_to_frame方法,可以很轻松的来解决这个问题。
autohtml.html
frame frame
inner.html
inner inner
click
frame.html 中嵌套inner.html
switch_to_frame()
操作上面页面,代码如下:
#coding=utf-8from selenium import webdriverimport timeimport osbrowser = webdriver.Firefox()file_path = 'file:///' + os.path.abspath('autohtml.html')browser.get(file_path)browser.implicitly_wait(30) # 它的用法应该比time.sleep() 更智能,后者只能选择一个固定的时间的等待,前者可以在一个时间范围内智能的等待。'''文档解释:selenium.webdriver.remote.webdriver.implicitly_wait(time_to_wait)隐式地等待一个无素被发现或一个命令完成;这个方法每次会话只需要调用一次time_to_wait: 等待时间用法:driver.implicitly_wait(30)'''#先找到到ifrome1(id = f1)browser.switch_to_frame("f1")#再找到其下面的ifrome2(id =f2)browser.switch_to_frame("f2")#下面就可以正常的操作元素了browser.find_element_by_id("kw").send_keys("selenium")browser.find_element_by_id("su").click()time.sleep(3)
效果:
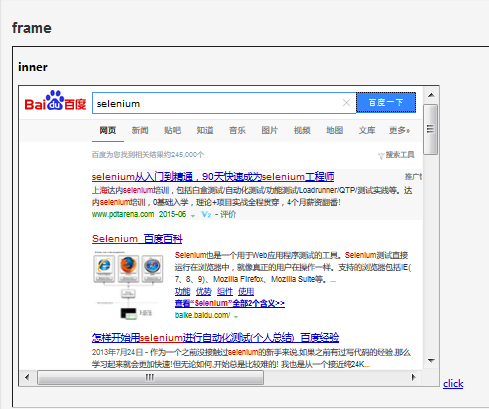
driver.switch_to_window()
有可能嵌套的不是框架,而是窗口,还有真对窗口的方法:switch_to_window
用法与switch_to_frame 相同:
driver.switch_to_window("windowName")
上传文件
上传过程一般要打开一个本地窗口,从窗口选择本地文件添加。所以,一般会卡在如何操作本地窗口添加上传文件。
其实,在selenium webdriver 没我们想的那么复杂;只要定位上传按钮,通send_keys添加本地文件路径就可以了。绝对路径和相对路径都可以,关键是上传的文件存在
upload_file.html
upload_file
upload.py
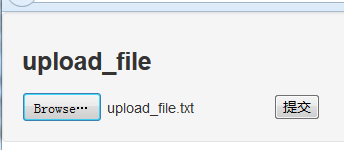
#coding=utf-8from selenium import webdriverimport os,timedriver = webdriver.Firefox()#脚本要与upload_file.html同一目录file_path = 'file:///' + os.path.abspath('autohtml.html')driver.get(file_path)#定位上传按钮,添加本地文件driver.find_element_by_name("file").send_keys('D:\\upload_file.txt')time.sleep(10)driver.find_element_by_id("submit").click()time.sleep(2) 效果:
处理下拉框
下拉框是我们最常见的一种页面元素,对于一般的元素,我们只需要一次就定位,但下拉框里的内容需要进行两次定位,先定位到下拉框,再定位到下拉框内里的选项。
drop_down.html
将上面的代码保存成html通过浏览器打开会看到一个最简单常见的下拉框,下拉列表有几个选项。
现在我们来选择下拉列表里的$10.69
#-*-coding=utf-8from selenium import webdriverimport os,timedriver= webdriver.Firefox()file_path = 'file:///' + os.path.abspath('drop_down.html')driver.get(file_path)time.sleep(2)m=driver.find_element_by_id("ShippingMethod")m.find_element_by_xpath("//option[@value='10.69']").click()time.sleep(2)driver.switch_to_alert().accept() 解析:
这里可能和之前的操作有所不同,首先要定位到下拉框的元素,然后选择下拉列表中的选项进行点击操作。
m=driver.find_element_by_id("ShippingMethod")
m.find_element_by_xpath("//option[@value='10.69']").click()
设置时会会弹出一个确定按钮;我们并没按照常规的方法去定位弹窗上的“确定”按钮,而是使用:
driver.switch_to_alert().accept()
完成了操作,这是因为弹窗比较是一个具有唯一性的警告信息,所以可以用这种简便的方法处理。
– switch_to_alert()
焦点集中到页面上的一个警告(提示)
– accept()
接受警告提示
Cookie处理
通过webdriver 操作cookie 是一件非常有意思的事儿,有时候我们需要了解浏览器中是否存在了某个cookie 信息,webdriver 可以帮助我们读取、添加,删除cookie信息。
打印cookie信息
#coding=utf-8from selenium import webdriverimport timedriver = webdriver.Chrome()driver.get("http://www.youdao.com")# 获得cookie信息cookie= driver.get_cookies()#将获得cookie的信息打印print cookiedriver.quit() 运行打印信息:
[{u'domain': u'.youdao.com', u'secure': False, u'value': u'aGFzbG9nZ2VkPXRydWU=', u'expiry': 1408430390.991375, u'path': u'/', u'name': u'_PREF_ANONYUSER__MYTH'}, {u'domain': u'.youdao.com', u'secure': False, u'value': u'1777851312@218.17.158.115', u'expiry': 2322974390.991376, u'path': u'/', u'name': u'OUTFOX_SEARCH_USER_ID'}, {u'path': u'/', u'domain': u'www.youdao.com', u'name': u'JSESSIONID', u'value': u'abcUX9zdw0minadIhtvcu', u'secure': False}] 对cookie的操作
上面的方式打印了所有cookie信息表,太多太乱,我们只想有真对性的打印自己想要的信息,看下面的例子
#coding=utf-8from selenium import webdriverimport timedriver = webdriver.Firefox()driver.get("http://www.youdao.com")#向cookie的name 和value添加会话信息。driver.add_cookie({ 'name':'key-aaaaaaa', 'value':'value-bbbb'})#遍历cookies中的name 和value信息打印,当然还有上面添加的信息for cookie in driver.get_cookies(): print "%s -> %s" % (cookie['name'], cookie['value'])# 下面可以通过两种方式删除cookie# 删除一个特定的cookiedriver.delete_cookie("CookieName")# 删除所有cookiedriver.delete_all_cookies()time.sleep(2)driver.close() 运行打印信息:
YOUDAO_MOBILE_ACCESS_TYPE -> 1_PREF_ANONYUSER__MYTH -> aGFzbG9nZ2VkPXRydWU=OUTFOX_SEARCH_USER_ID -> -1046383847@218.17.158.115JSESSIONID -> abc7qSE_SBGsVgnVLBvcukey-aaaaaaa -> value-bbbb # 这一条是我们自己添加的